How to balance edge and cloud in modern IoT deployments
April 07, 2026In IoT architecture, edge and cloud computing are often presented as alternatives. Actually, they are complementary layers of the same system. Modern IoT deployments, from smart buildings to industrial automation and distributed energy, rely on a deliberate split of responsibilities between local execution and centralized intelligence. The real question is not edge or cloud, but what runs where and why. This article provides a practical breakdown for IoT architects and technical decision-makers who need to design systems that are responsive, resilient, and scalable.
What edge and cloud mean in IoT architecture
In an IoT context, edge computing refers to processing that occurs on or near devices, typically on gateways, controllers, embedded computers, or site-level edge servers. Data is analyzed and acted upon locally, minimizing round-trip latency to a remote data center. Cloud computing aggregates data from many devices and sites into a centralized infrastructure. It enables large-scale storage, advanced analytics, machine learning, fleet-wide orchestration, and user-facing applications.
A useful model:
- Edge = reflex layer (milliseconds to seconds);
- Cloud = brain layer (minutes to months).
The reflex layer executes immediate control logic, such as threshold checks, safety shutdowns, or actuator adjustments. The brain layer performs optimization, trend analysis, AI model training, and portfolio-level reporting. This distinction directly impacts latency, cost, reliability, and compliance.
Edge vs cloud: key architectural differences
The table below summarizes the primary trade-offs in IoT-focused deployments.
| Aspect | Edge computing (IoT-focused) | Cloud computing (IoT-focused) |
|---|---|---|
| Latency | Near real-time for local decisions; no WAN dependency. | Higher due to network round-trip. |
| Bandwidth cost | Sends filtered, summarized, or event-driven data; raw streams reduced. | Can require high bandwidth if raw telemetry is centralized. |
| Availability | Continues operating during cloud or WAN outages. | Dependent on stable connectivity for central control. |
| Security & privacy | Sensitive data can remain on-site; reduced exposure in transit. | Larger attack surface; more data traverses external networks. |
| Scale & analytics | Limited compute; suitable for rules, filtering, and lightweight models. | Virtually unlimited scale; strong for ML, historical analytics, cross-site orchestration. |
These differences define how your system behaves under stress, such as network failures, traffic spikes, or security incidents. For example, in a manufacturing plant, a robotic arm cannot wait for a cloud round-trip to stop when torque exceeds a safe limit. In contrast, optimizing preventive maintenance intervals across 200 plants requires centralized analytics on years of historical data. Each layer solves a different class of problems.
When to lean on edge
Edge computing becomes essential when responsiveness, resilience, or data locality are non-negotiable.
Typical edge-first scenarios include:
- Sub-second control loops (PLC-style automation, elevator systems, robotic cells, safety interlocks).
- Intermittent or expensive connectivity (remote substations, transport fleets, offshore sites).
- Strict data residency requirements (healthcare telemetry, occupant-level building data, proprietary industrial processes).
- High-volume raw telemetry (vibration sensors, high-frequency electrical measurements, machine vision pre-processing).
A practical example of this approach can be seen in our implementation of edge-based energy monitoring and control, where local logic executes independently of cloud availability. At the edge, common architectural patterns include local rule-based automation (if/then logic); anomaly detection on sensor streams; data filtering and compression, protocol translation (e.g., Modbus, BACnet, CAN to MQTT or HTTPS); local alerting and fallback control during WAN outages. In smart buildings, for example, CO₂-based ventilation control must execute locally. If occupancy spikes, air-handling units must respond immediately. Waiting for a cloud decision would introduce unnecessary latency and potential discomfort.
In industrial environments, the stakes are higher. A robotic arm cannot wait for a cloud round trip to stop when torque exceeds a safe limit. This becomes especially critical in real-time hydrogen safety monitoring systems, where alarm logic and shutdown conditions must operate locally without relying on WAN connectivity. Edge is also a cost control mechanism. Streaming high-frequency telemetry from thousands of devices directly to the cloud can create unnecessary bandwidth and storage costs. Filtering and summarization at the edge reduce data volume before transmission. However, the edge has constraints. Compute and storage are finite. Managing distributed edge nodes at scale introduces operational complexity. That is where the cloud complements the architecture.
When to lean on cloud
Cloud computing excels where scale, aggregation, and cross-site intelligence matter more than immediate reaction time.
Cloud-first scenarios include:
- Historical analytics and trend analysis across months or years.
- Predictive maintenance models trained on fleet-wide datasets.
- Portfolio-level KPIs across multiple buildings, factories, or regions.
- Centralized dashboards and governance with role-based access.
- Multi-tenant SaaS environments serving multiple customers.
- Remote configuration and firmware management.
In industrial IoT, cloud platforms often host digital twins, advanced anomaly detection models, and AI-based optimization engines. These workloads require computational resources and datasets that exceed the capacity of a single site. In energy monitoring systems, for example, local devices measure voltage, current, and power factor in real time. The cloud aggregates this data across facilities to calculate benchmarking metrics, support carbon reporting, and optimize demand response. Cloud platforms also simplify lifecycle management. Instead of updating the logic separately on hundreds of gateways, orchestration can be centrally controlled and managed. Yet cloud-only architectures introduce risk if overused. If critical control depends entirely on connectivity, outages become operational failures. That is why hybrid designs dominate serious IoT deployments.
The hybrid edge-cloud model as the default
For most production-grade IoT systems, a layered hybrid architecture provides the best balance. Lets see how a typical three-layer structure looks like below.
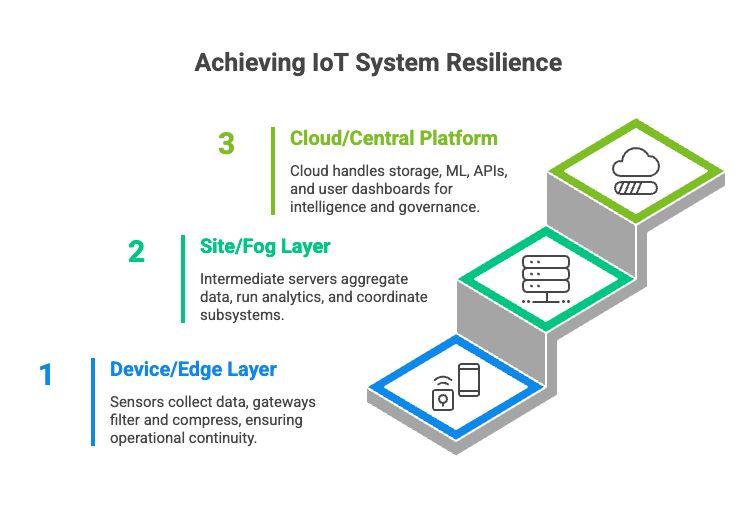
1. Device / edge layerSensors and actuators collect raw telemetry.
- Edge gateways perform filtering and compression, execute real-time rules, and handle local alarms and safety logic.
- Data buffering ensures continuity during WAN disruptions.
- This layer guarantees operational continuity and fast reaction.
2. Site / fog layer (optional)
- In larger facilities, an intermediate site server aggregates data from dozens or hundreds of devices.
- It runs richer analytics (e.g., occupancy heatmaps), coordinates multiple subsystems (HVAC, lighting, energy), caches data during extended connectivity loss, and provides local dashboards.
- This layer reduces load on the cloud and adds local coordination capabilities.
3. Cloud / central platform layer
The cloud layer typically handles:
- Long-term storage.
- Cross-site aggregation.
- Machine learning training and inference (where latency allows).
- APIs and integrations (BMS, CMMS, ERP, billing systems).
- User-facing dashboards and reporting.
- Role-based access and tenant management.
In this setup, the edge focuses on control and data conditioning. The cloud focuses on intelligence, governance, and orchestration. Latency-sensitive logic stays close to the physical process. Computationally intensive and portfolio-wide logic lives centrally. This separation improves system resilience. If the cloud is temporarily unavailable, local control continues. If a gateway fails, central analytics remain intact.
Practical takeaways for IoT architects
When designing your next IoT system, consider the following principles:
- Keep safety and SLA-bound control at the edge. Any function that must operate during network failure should execute locally.
- Use the cloud for scale and intelligence. Historical analytics, AI training, and cross-site benchmarking belong in a centralized infrastructure.
- Define a clear data pipeline. Explicitly decide what stays local (raw data), what is summarized, and what is transmitted (metrics, events, metadata).
- Design for intermittent connectivity. Assume WAN disruptions will happen and ensure graceful degradation.
- Plan edge fleet management from day one. Distributed nodes require secure provisioning, updates, and monitoring.
- Treat hybrid as the baseline, not the exception. Modern IoT platforms assume workload distribution between edge and cloud.
The most common architectural mistake is pushing too much logic into one layer. Cloud-only systems struggle with latency and resilience. Edge-only systems struggle with analytics and scale. Balanced systems define responsibilities deliberately.
Final perspective
Edge and cloud are not rivals. They represent different execution domains within the same distributed architecture. Edge provides immediacy, autonomy, and data locality. Cloud provides scale, intelligence, and coordination. The strategic decision is not which one to choose – it is how to partition your workloads based on latency tolerance, compliance requirements, bandwidth constraints, and operational scale. In serious IoT deployments, the answer is almost always hybrid.

